



ChatGPT can't grade essays — yet.
Unacceptably high variability in the assessment of writing


I’ve been curious about ChatGPT’s ability to assess student writing and provide quality feedback. There are many ways to test this, but a simple method is to experiment with rubrics.
I became interested in exploring this when I heard a talk at the International Conference on Machine Learning in Honolulu this summer. The presenter had conducted research showing that ChatGPT cannot successfully complete planning tasks. Planning tasks require following specific steps in a specific order, like planning a wedding or baking a cake. I have read many articles and posts by respected AI evangelists that present alternate thinking, actively encouraging AI users to build prompt libraries that utilize ChatGPT to complete simple route tasks reliably. For simple tasks, AI produces useful and quality results. I began to wonder which category of task grading students’ written work fell in. Is assessing the quality of writing using a well-formed rubric more like a planning task or is it a route task?
To explore this further, I conducted a simple exploration of ChatGPT’s ability to assess the quality of writing using a rubric reliably.
First, I collected two rubrics. The first rubric that I used was from the College Board. The rubric was used to grade the Argumentative Essay portion of the AP English Language and Composition exam. The second rubric that I used came from ChatGPT itself. I asked ChatGPT to create a robust rubric to assess writing quality in general.
I then collected three writing samples to have ChatGPT assess the quality of using both rubrics, using three opinion pieces from the New York Times, each published on September 2, 2023.
Once I had the two rubrics and three articles, I wrote code to have ChatGPT assess the quality of each of the three articles using the GPT-4 model and again using the GPT-3.5-Turbo model. After assessing one article with one of the models and one of the rubrics, I cleared/reset the context window. This means that each time ChatGPT assessed a piece of writing, it was as if it was doing so for the first time with no memory of previous grading attempts. I then repeated the process until each combination of rubrics, models, and essays was used 50 times each. This means that ChatGPT graded the same essay with the same model, using the same rubric 50 times, and repeated the process until each combination of model, article, and essay had been used.
The results were intriguing because ChatGPT was inconsistent in its assessment of each piece of writing. ChatGPT’s assessments varied so greatly that they wouldn’t be usable in a school context. GPT-4 was more consistent than GPT-3.5-Turbo but still showed considerable variation in the assessment of the quality of each essay.
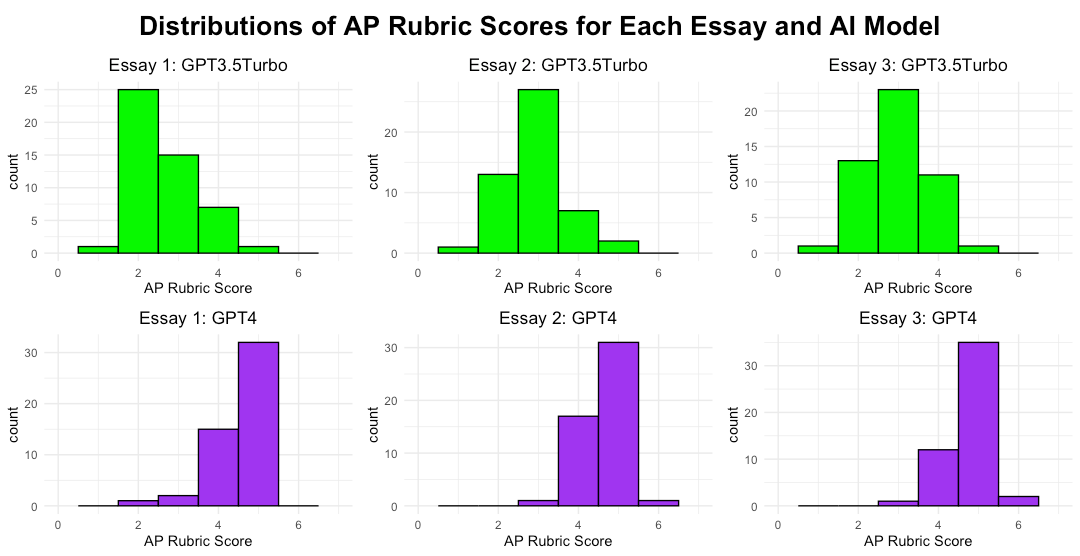

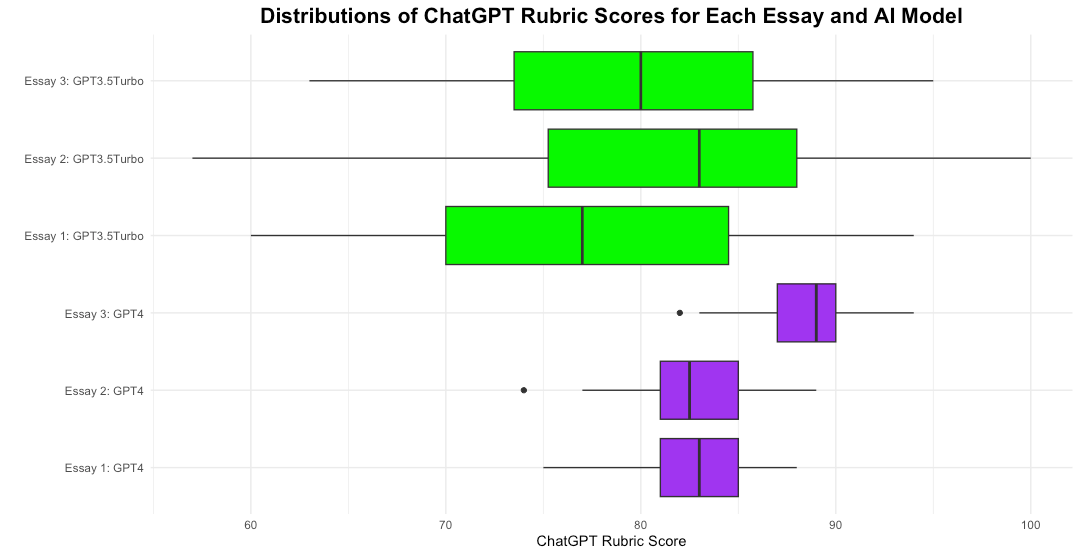
I’m unaware of teachers who have seriously begun using ChatGPT to assess students' writing. However, I’ve read multiple articles suggesting that ChatGPT could be a valuable tool providing students with critical feedback on their writing, helping them to improve their work. My findings don’t directly assess the quality of feedback that ChatGPT gives students, but it does raise questions and concerns regarding the variability in the quality of that feedback.
The College Board rubric is reasonably specific and straightforward. It was designed to help reduce variation in the assessment of students’ writing. This raises many questions in my mind.
Given a specific rubric, was there variation in how the rubric was interpreted?
Was there variation in what aspects of the writing ChatGPT focused on?
Was there simple variability in how it interpreted the writing?
Was the variance related to the temperature setting in ChatGPT? (If you haven’t read about it, the temperature setting in ChatGPT is worth a few moments of your time).
Does a change in the temperature setting increase the variance in rubric scores predictably?
Do these results give any insight into the nature of grading and its task genre? I would agree that grading is more complex than baking a cake, but it doesn’t feel as complicated as planning a wedding. How complex of a task is it with respect to reasoning skills?
Does variability matter if the quality of the feedback is generally good? How good is the quality of ChatGPT’s feedback on writing compared to a teacher’s?
There is much more to be studied here. I plan to run a few more experiments, and I’m sure other researchers are doing similar or more robust studies. In the meantime, these findings provide some insight into ChatGPT’s variability in assessing writing. ChatGPT shouldn’t be trusted to assess student writing — yet.
Resources and Citations:
Here are links to the two rubrics that I used in the study.
Here are links to the three New York Times articles that I used in the study.
Here is a link to a sample of the core code I used to conduct this experiment. You can try this experiment for yourself by entering your own OpenAI API key, rubric, and writing sample.
Here is a link to the data set of rubric scores.
Please reach out with questions, comments, suggestions, or ideas for a collaboration.
This paper is a bit more optimistic about rubrics to grade student work. Even if the papers were ordered from lowest to highest score, it would make grading more efficient.
https://community.wolfram.com/groups/-/m/t/2958774
Thanks for sharing!