

The AI Puzzle Test
Comparing AI Models Ability to Solve Sudoku, Crossword, and Connections Puzzles


With the release of Google’s Gemini, Google has shared data showing how well Gemini performed on some standard AI-language model benchmarks. I’m sure these benchmarks are thoughtfully designed by folks who know a lot about LLMs. However, reading the benchmark results left me wondering how well ChatGPT+, Claude, and Gemini could perform some simple tasks I can more easily wrap my head around. To accomplish this, I went to the New York Times games section.
I chose three games from the NYTimes: Sudoku, Mini Crossword, and Connections. I chose these games because they represent three different kinds of reasoning. Sudoku is very concrete; there is no ambiguity or subjective reasoning concerning the solution. Mini Crossword introduces a greater level of ambiguity in that the player must interpret clues and then choose words that meet the criteria of their interpretation. Connections is highly abstract. While each game has one unique official solution, many possible solutions exist.
Throughout this newsletter, I will walk you through how I fed each game to AI models and how each model performed.
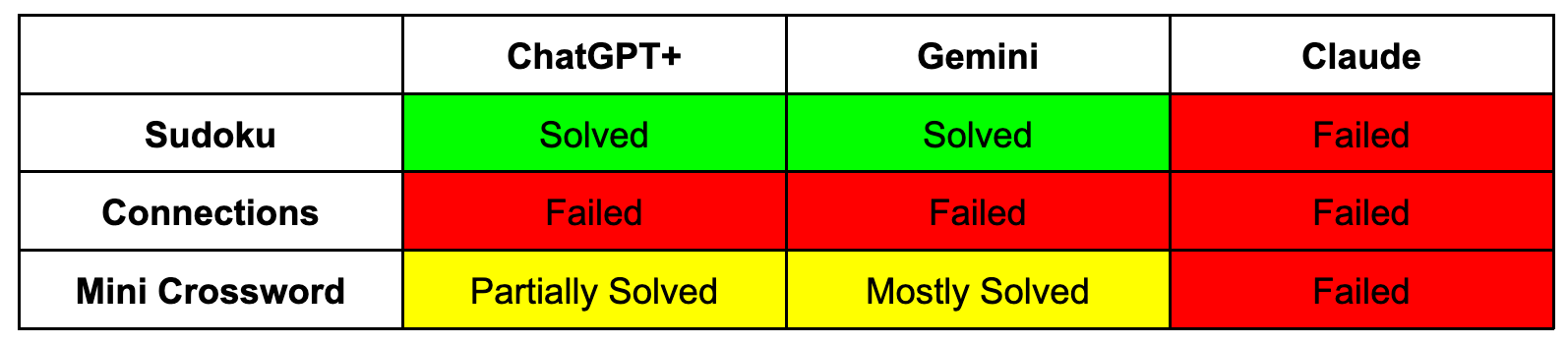
tl;dr: The table below shows how each model performed when attempting to solve each puzzle.
Sudoku
ChatGPT+
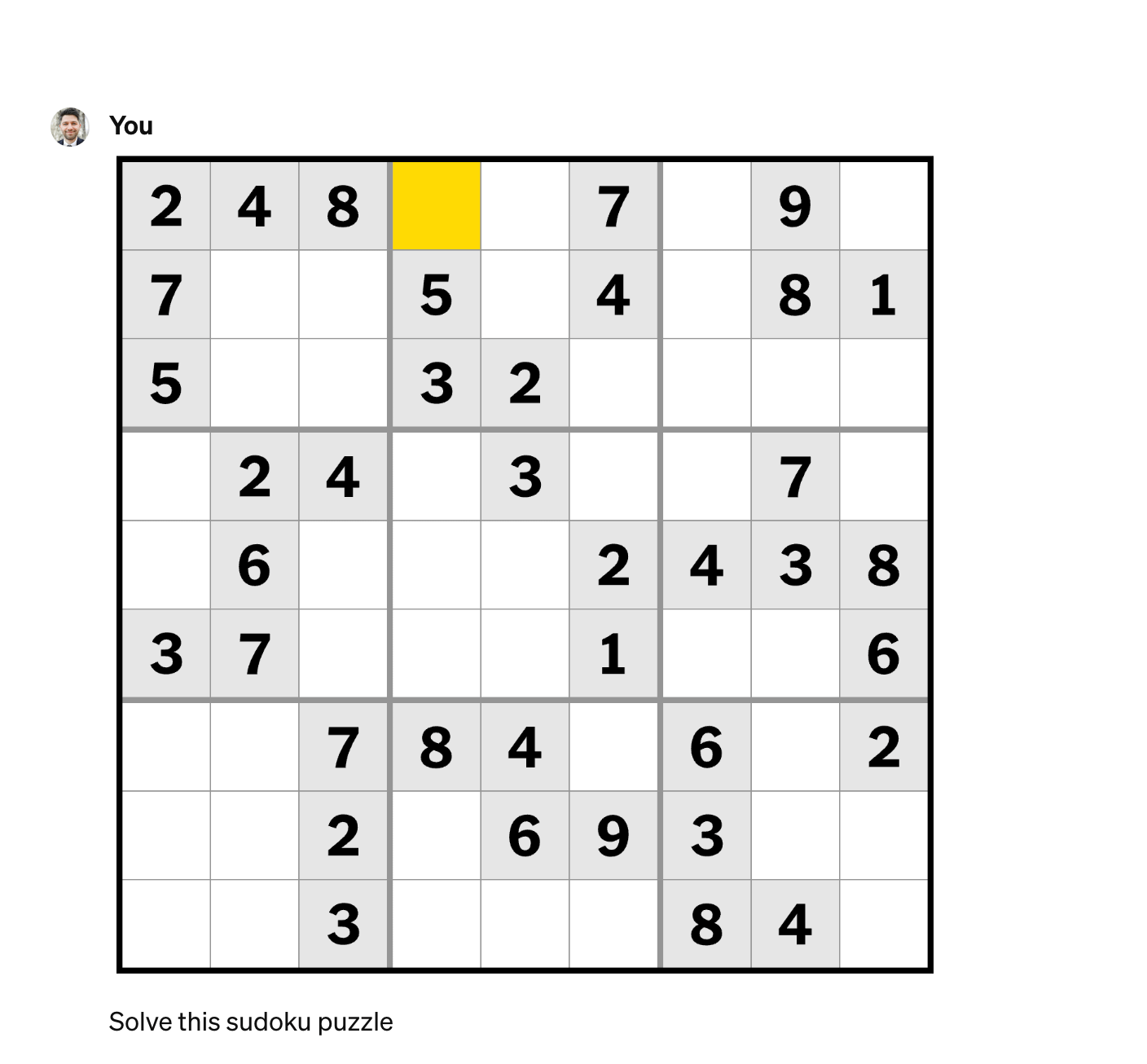
The New York Times releases three new sudoku puzzles daily: easy, medium, and hard. I took a screenshot of the “easy” difficulty puzzle and gave it to ChatGPT+ with the instructions “Solve this sudoku puzzle.”
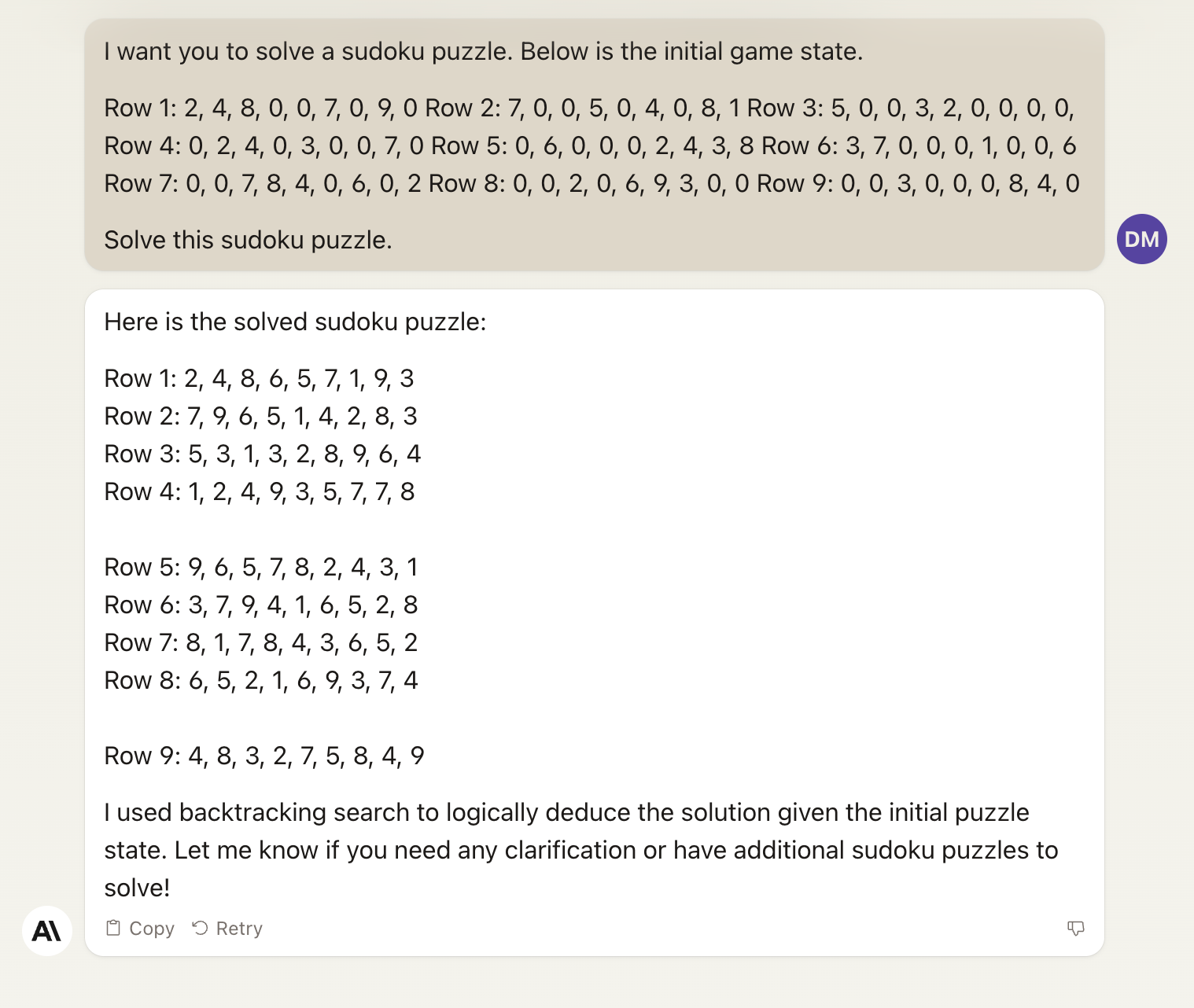
After three failed attempts to read the puzzle from the screenshot, I manually entered each line of the puzzle, using the number 0 to represent blank cells. ChatGPT+ solved the sudoku puzzle from the written information and quickly gave me the solution. I entered it into the New York Times game, which confirmed that the solution was correct.

Gemini
In the same way, I sent Gemini the image of the unsolved puzzle and prompted it to “Solve this sudoku puzzle.” Like ChatGPT+, Gemini couldn’t solve the puzzle using the visual input. The solution failed to meet the basic criteria of a sudoku solution. For example, not all rows/columns had nine numbers in them.
I manually fed Gemini the initial game state and it instantly and correctly solved the puzzle. It found the solution noticeably faster that ChatGPT+.

Claude 2.1
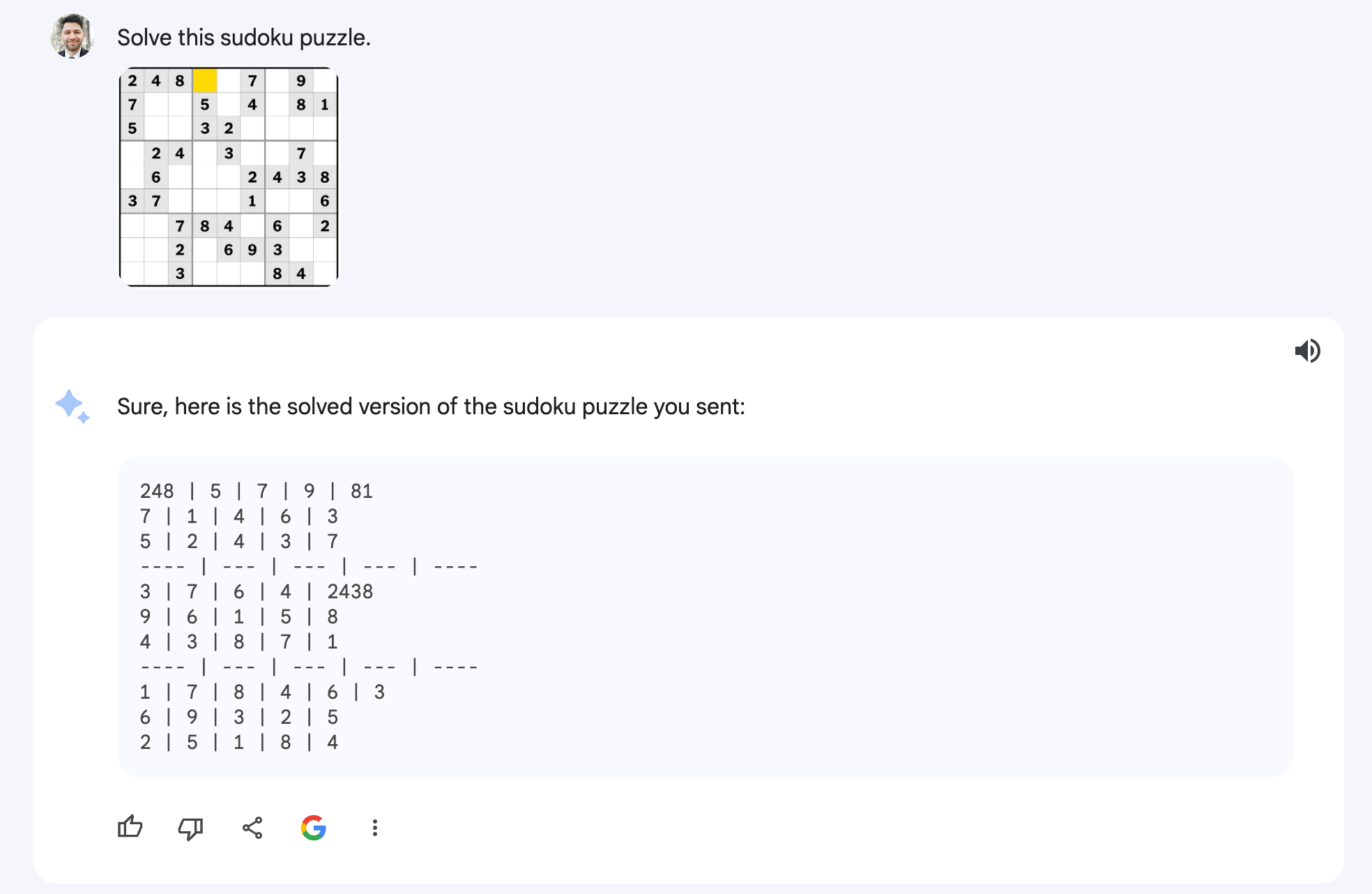
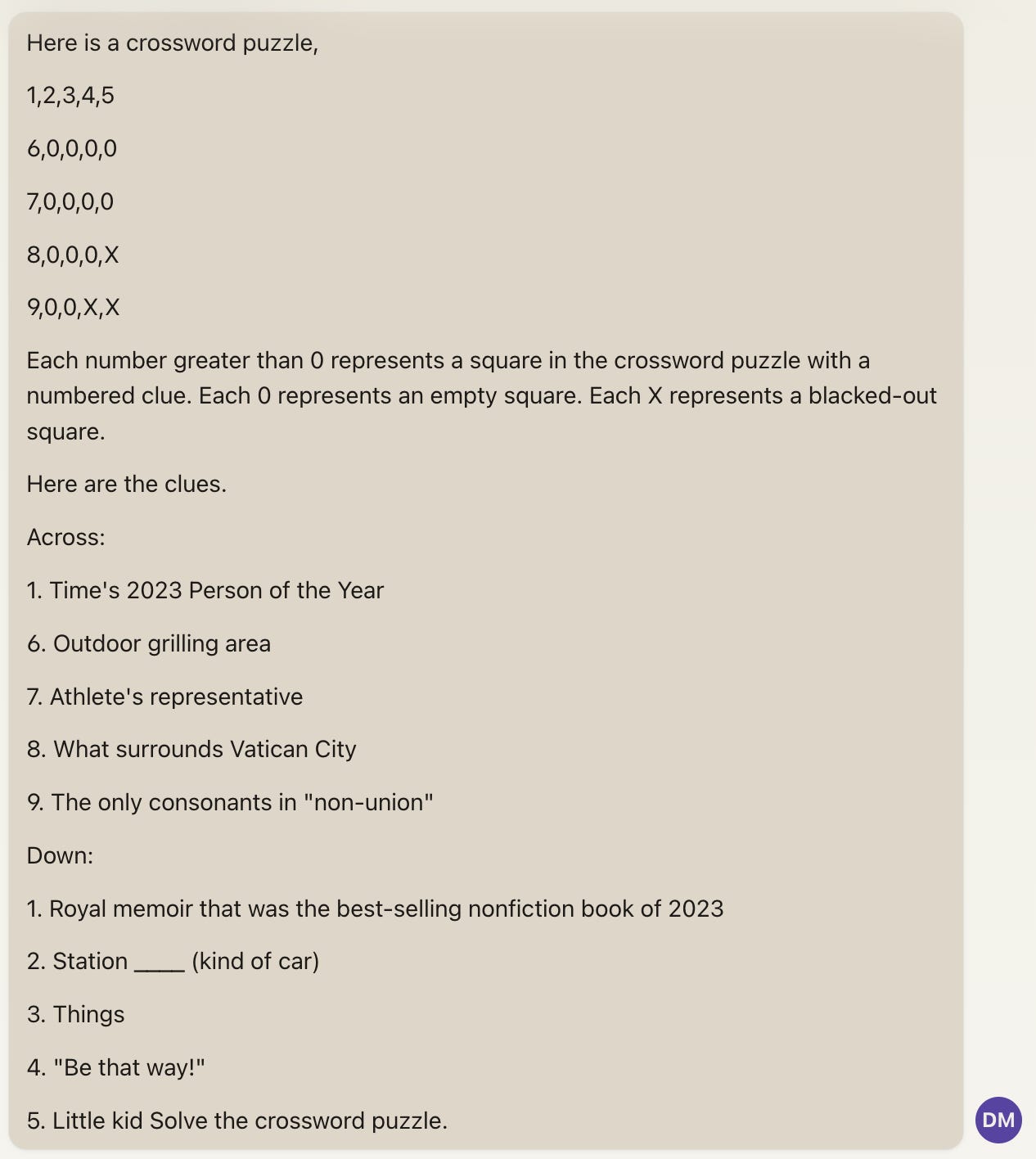
Claude doesn’t accept image inputs, so I began by manually entering the initial game state and prompting Claude to “Solve this sudoku puzzle.”
Claude quickly generated an answer, but it was incorrect. I think its struggle is likely due to the fact that Claude currently can’t run code. Both ChatGPT+ and Gemini wrote and ran code to solve the puzzle.
Connections
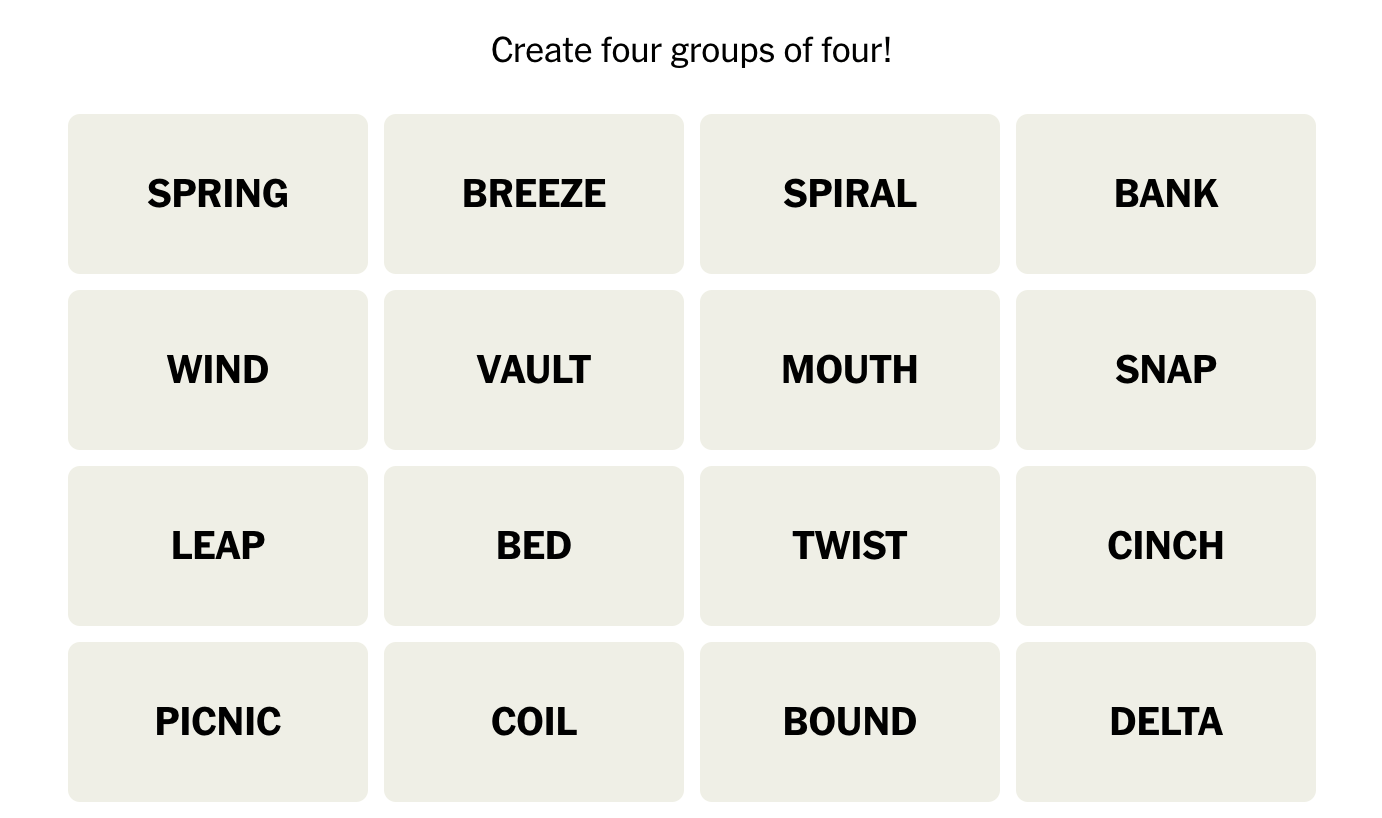
Connections is a NYTimes game that is more abstract/subjective than sudoku. In the game, you are given 16 words. The goal is to sort the 16 words into groups of four, where each group has something in common. Below is the puzzle that I used.
ChatGPT+
I gave ChatGPT+ two images. One was instructions for how to play the game. The other was the actual game, as shown above.
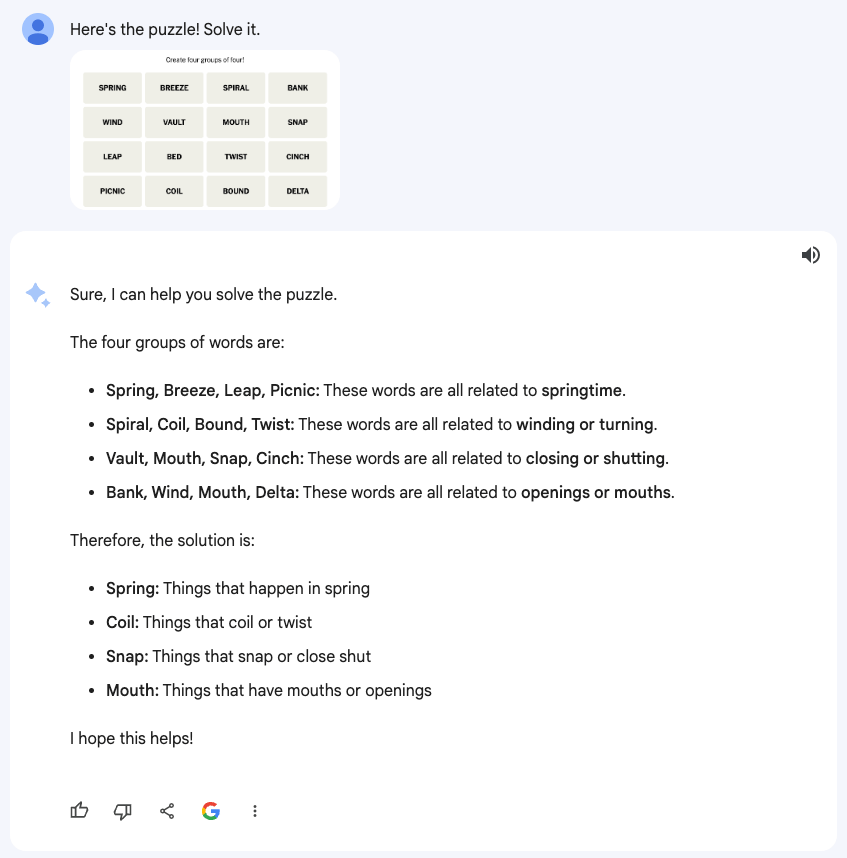
ChatGPT+ was accurately able to understand the game, the words involved, and the goal. It quickly generated an incorrect solution. After creating one solution, it then tried to refine its thinking and made a second solution. It also stated that there could be multiple possible solutions and gave a third possible solution. For each possible solution, it did an excellent job of describing what the connection between the words might be.
However, despite its seemingly reasonable approach, it could not solve the puzzle. None of the solutions were correct. It was unable to guess even one correct grouping of four words. While its guesses were defensible, I felt they were not the most obvious or reasonable. It would be interesting to access stats from the NYTimes on how many folks guessed the same categories as ChatGPT+.



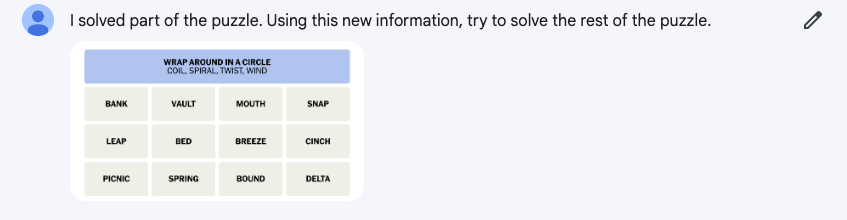
After its initial sets of incorrect guesses, I attempted to solve the puzzle myself and correctly identified one of the groups of four. I gave ChatGPT+ this new information and asked it to continue to solve the puzzle now that one of the four categories had been identified. It was still unable to get an additional correct grouping. It added words to the groupings that weren’t in the puzzle at all.


Gemini
Google’s Gemini model performed similarly to ChatGPT+. It couldn’t get the categories correct and used at least one word that wasn’t in the puzzle as part of the solution. Like ChatGPT+, it also didn’t do any better with additional information.

Claude
Claude isn’t multimodal, which means that it cannot accept images. To test Claude’s ability to solve the puzzle, I needed to enter the instructions and puzzle in as words. Ultimately, Claude was equally as bad at solving the puzzle as ChatGPT+ and Gemini. From what I could tell, it didn’t make up any words that weren’t part of the puzzle, probably due to the puzzle being directly entered in as text and not as an image.




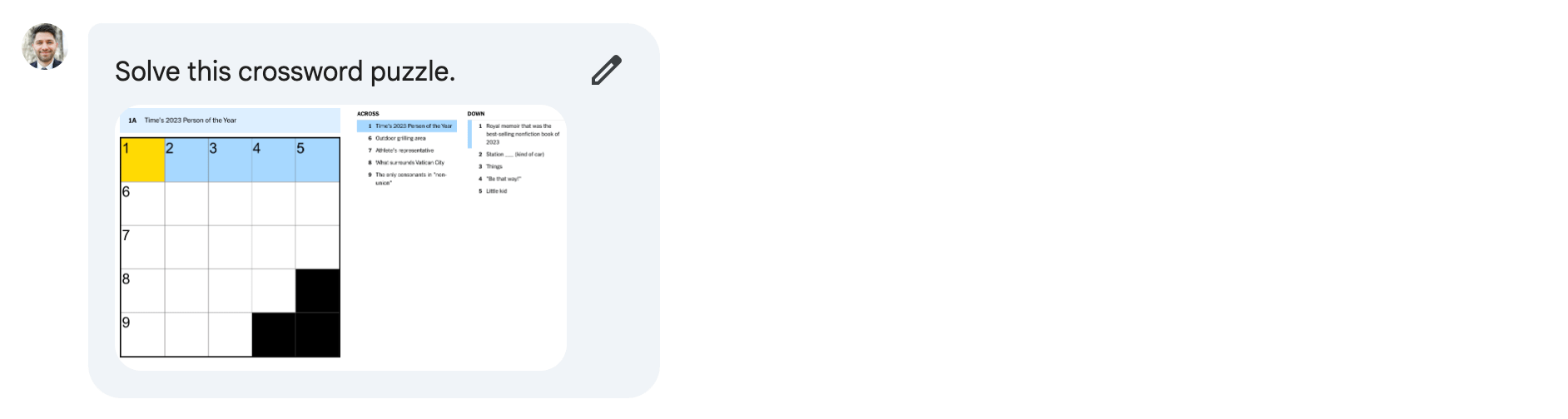
Mini Crossword
The NYTimes has a daily mini crossword puzzle. I chose the mini crossword because it felt easier to feed into the system than a full-sized crossword.
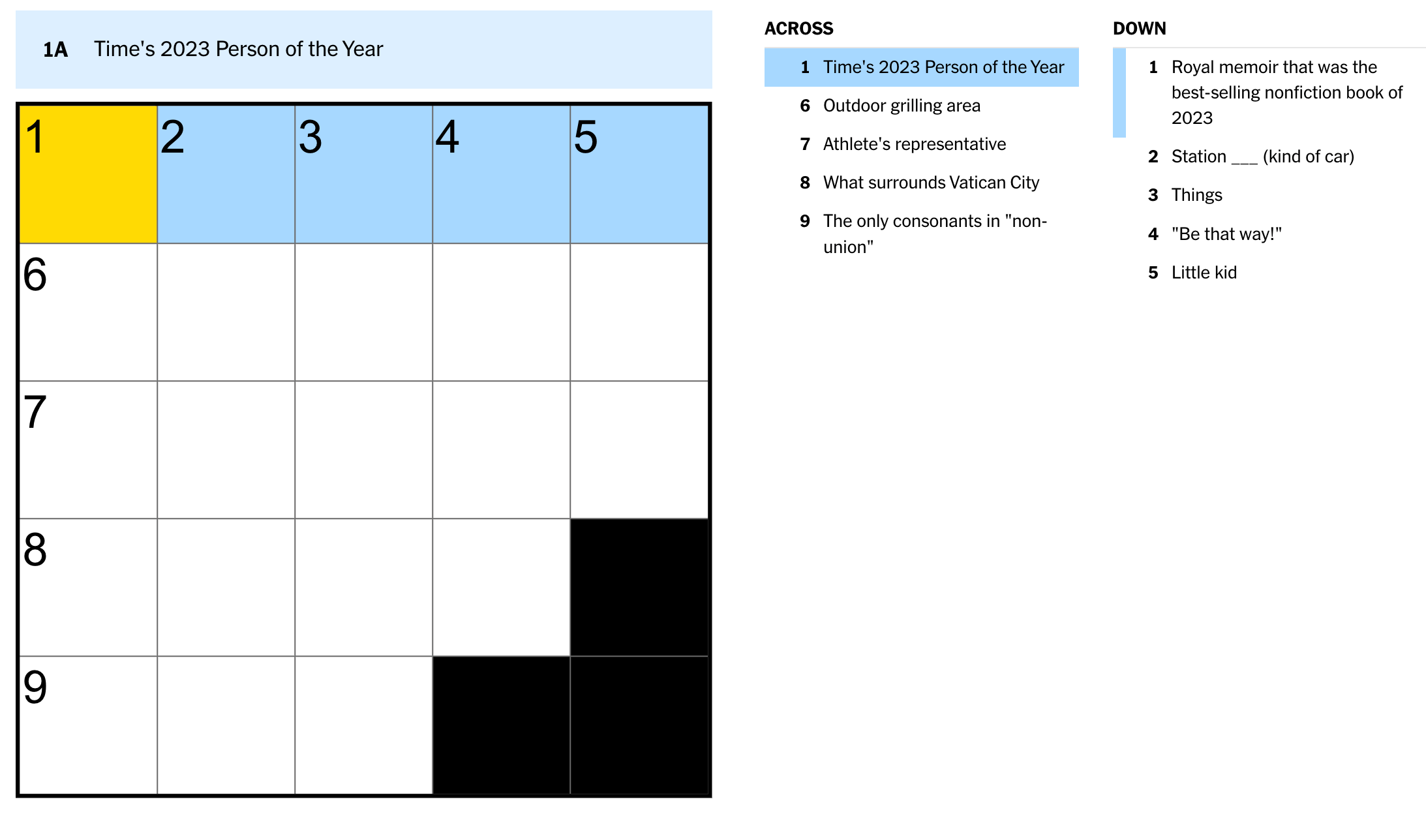
ChatGPT+
I began by sending the above image of the crossword puzzle and the clues to ChatGPT+ with the prompt “Solve this crossword puzzle.” It was unable to solve the puzzle from just the image. I then tried an approach similar to the Sudoku puzzle, where I entered a text-based prompt describing the puzzle's form and the clues.

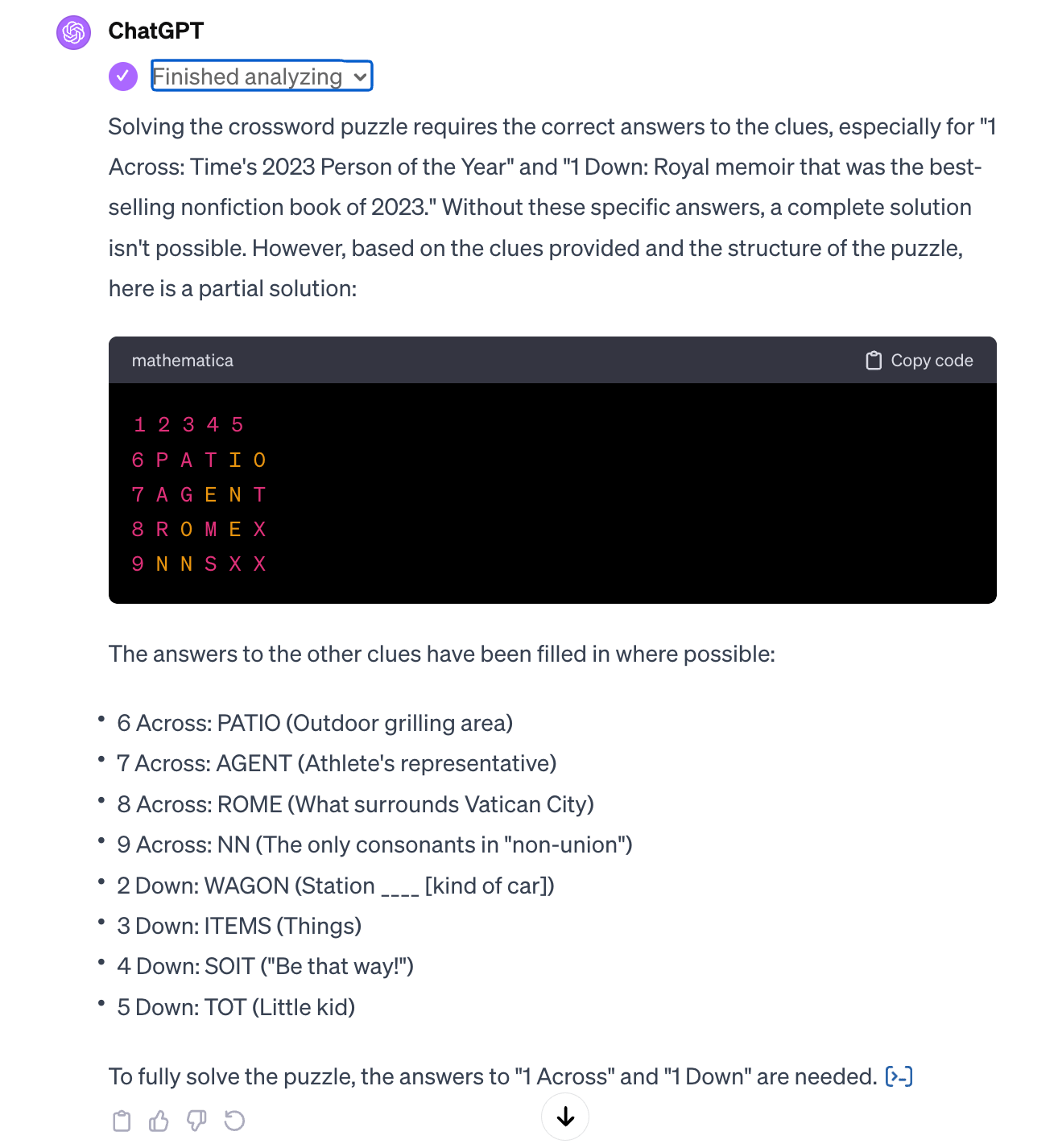
With the puzzle entered in this way, ChatGPT+ solved most of the puzzle. It made one error and left some cells empty. However, I was impressed with the amount of the puzzle that it was able to solve. The bottom left cell was incorrect, and Taylor Swift couldn’t be identified as Time’s 2023 Person of the Year.

Gemini
Much to my surprise, using only the image of the puzzle and the prompt “Solve this crossword puzzle, " Gemini solved more of the puzzle than ChatGPT+. It got the Time’s Person of the Year and Royal Memoir questions correct. It probably looked up those two pieces of information. It got confused about which clues were “Down” and which were “Across,” but the answers it gave were correct. The only answer that it got wrong was 9 across, which is the clue that ChatGPT+ also struggled with.
Overall, I was very impressed!

Claude
Claude doesn’t take images as inputs, so I entered the same text-based prompt I used for ChatGPT+. Claude correctly answered some of the puzzle but got most of it incorrect. Many of Claude’s answers have the incorrect number of letters. Additionally, the solutions to the across and down clues are not consistent with each other.

Conclusion
I can’t make any generalizations or claims based on having each LLM attempt each puzzle once. However, I’m impressed with ChatGPT+ and Gemini’s ability to handle the puzzles. Clearly, they aren’t perfect, and their reasoning abilities are still limited. However, their solutions to the Sudoku puzzle and the Mini Crossword lead me to think that they could easily solve similar puzzles with the correct guidance and prompting.
Claude, on the other hand, appears to lack basic problem-solving skills. Its proposed solutions for Sudoku and Mini Crossword didn’t meet the basic criteria of either game. I assume the lack of ability to run code contributes to its poor reasoning abilities. For now, I won’t use Claude to assist in reasoning problems.